
Do you get this error when applications try to establish a connection to Cassandra?
2019-08-10 14:03:51,698 ERROR [com.datastax.driver.core.Cluster] (Production Cluster-reconnection-0) Authentication error during reconnection to 10.0.10.10/10.0.10.10:9042, scheduling retry in 32000 milliseconds
com.datastax.driver.core.exceptions.AuthenticationException: Authentication error on host 10.0.10.10/10.0.10.10:9042: Error during authentication of user app-01 : org.apache.cassandra.exceptions.UnavailableException: Cannot achieve consistency level LOCAL_ONEThis is confusing. Maybe it’s true that one nodes is down. But this cluster has multiple nodes, and you are contacting one that is working fine. So why does it say that LOCAL_ONE consistency level cannot be achieved?
Even more: you didn’t ask for that consistency level in any part of the application code. Up to that point, you’re just trying to connect!
TL;DR: If you just want to copy/paste a solution, jump to How to fix the problem.

Why it happens
Whenever a client connects, Cassandra runs a query against its system tables to check if the provided credentials are correct. This query is ran with the LOCAL_ONE consistency level.
This explains part of the error. But probably you still don’t understand why this query fails.LOCAL_ONE tells the node that received the query: this query must be answered by a single node, which must be located in the same datacentre where you are. This differs from other consistency levels in these ways:
- There is no need to contact other nodes to check if data is correct. So there is less latency, compared to any consistency level stricter than
ONE. - With consistency levels stricter than
ONE, If the data to return is not fully consistent, a small repair is triggered. This operation is more lightweight if it doesn’t involve traffic between datacentres. LOCAL_ONEsays that the node that answers your query must be local. With theONEconsistency level there is no such restriction, so the query could cause cross-datacentre traffic (higher latency).
This may still be confusing, if you’re new to Cassandra: the node that answers the query should be the one you contacted, right? Well, not necessarily.
As you know, in Cassandra all keyspaces have a replication factor – a number that indicates how many nodes contain each row. The rows are then automatically – and hopefully evenly – distributed across the nodes, in a way that you can’t control. If the replication factor is equal to the number of nodes, all nodes have all the data and can answer any query. But if it’s lower, often nodes cannot find the results themselves, and will send the query to a node that has the data. In this case, it is possible that all nodes containing the data you are looking for are down; thus, even if you contacted a running node, it cannot return results. This risk is higher with stricter consistency levels. The corner case is ALL, which means that all nodes containing the desired rows must be up and agree on the results.
For example, check the figure below. Each node (1, 2, 3) contains three sets of rows (A, B, C). If a client contacts node 1 with a query that returns rows from set C, node 2 or node 3 will have to be involved in the query execution.
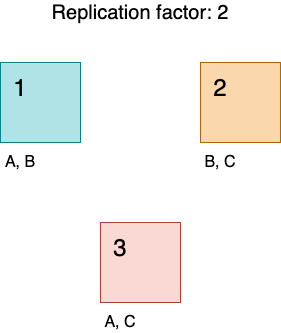
The data used for authentication is located in the system_auth keyspace. Its default replication factor is 1: so each data portion is located on one node, and if that node is down LOCAL_ONE cannot be satisfied.
Now check the figure below. If any node is down, part of the rows are not available.
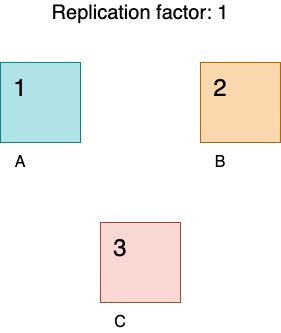
Why is there no redundancy by default? Probably because at the very beginning of its life, every cluster consists of one node.
How to fix the problem
Just run this command:
ALTER KEYSPACE system_auth
WITH replication = {
'class': 'NetworkTopologyStrategy',
'<datacentre_name>': <number_of_nodes>
};This CQL command will increase the replication factor to the number of nodes. Every node will contain a copy of all the rows in the system_auth keyspace, and therefore each node will allow clients to login – even in the unfortunate case that every other node is unreachable. This is typically what you want.
This keyspace is typically very small, so this is a lightweight operation.
If you are having this problem, it may be an indicator that you didn’t configure certain aspects of your Cassandra cluster optimally. You may want to consider a Cassandra Health Check from Vettabase.
Federico Razzoli




0 Comments